DataFrames is the 2-dimensional, tabular representation of the data in tuple format containing the information about the dimensionality of DataFrame in Pandas. The dimensionality of the DataFrame has information about row_labels and column_names. However, most of the time, when dealing with a dataset for data wrangling, there is a need to clean the data first to get useful insights from the data. The cleansing of data includes dropping rows in pandas DataFrame or deleting columns in Python that contain NaN or None values.
This article will demonstrate dropping rows in Pandas DataFrame in Python. For demonstration, the article covers the following prevalent approaches:
- How to Drop Rows in Pandas DataFrame in Python?
- Use Case 1: Using “drop()” Function by Considering Index Label
- Use Case 2: Using “drop()” Function by Specifying the “axis” Parameter
- Use Case 3: Using the “drop()” Function by Slicing
- Use Case 4: Dropping Rows by Utilizing “inplace” Parameter
- Use Case 5: Dropping Rows by Accessing Index Parameter
- Use Case 6: Dropping Rows by Considering Index Double Bracket Notation
- Use Case 7: Dropping Rows by Considering Index Slicing
- Use Case 8: Dropping Rows by Utilizing drop() function Only
- Use Case 9: Dropping Rows by Utilizing “iloc” as Attribute
- Use Case 10: Dropping Rows by Utilizing drop() function Only
- Use Case 11: Dropping Rows by Utilizing the “dropna” Function
- Use Case 12: Conditional Dropping Rows in DataFrame
How to Drop Rows in Pandas DataFrame in Python?
To drop rows that contain missing values, NaN, Null, or Null values, you can utilize a built-in function to delete the row from the DataFrame in Python to get rid of them. One of the common approaches to drop rows in Python is to implement the “drop()” function on the DataFrame. Following are the use cases to utilize the drop() function in different scenarios:
Use Case 1: Using “drop()” Function by Considering Index Label
To drop rows in Pandas DataFrame in Python, you need to specify an index label within the “index” parameter in the DataFrame() braces (the index label is by default, it is defined in our case). Then define the targeted index label within the index operator ([ ]) of the drop() function. Here’s how you can utilize the drop() function to drop rows in Pandas DataFrame in Python:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
index_label=['0','1','2']
# Drop rows by Label indexing
df1 = pd.DataFrame(dict ,index=index_label)
print("\nDataFrame", df1)
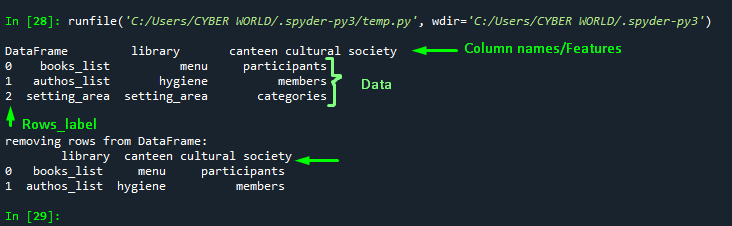
df2 = df1.drop(['2'])
print("\n\nremoving rows from DataFrame:\n", df2)Output
Use Case 2: Using “drop()” Function by Specifying the “axis” Parameter
In the tabular representation of the DatFrame the data is represented as two-dimensionality. One is rows that have a defined “axis=0”, and another is a column having “axis=1”. The dimensionality gives an idea about how many rows and columns you are dealing with. To drop rows in Pandas DataFrame in Python, utilize the “labels” and “axis” parameters. The “axis” is “0”, if the target is “rows” and within the “labels” parameter, set the targeted rows that you want to drop within the index operator “[ ]”. Here’s how you can drop rows by considering the “axis” parameter in Pandas DataFrame:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
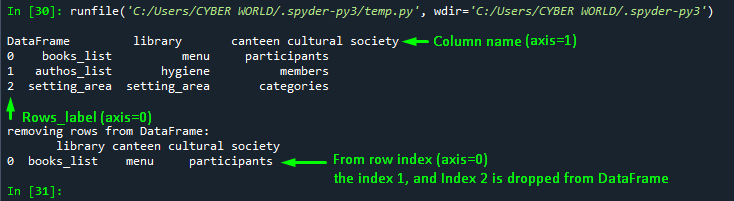
df2 = df1.drop(labels=[1,2],axis=0)
print("\n\nremoving rows from DataFrame using Label :\n", df2)
#using range() FUNCTION
df3= df1.drop(labels=range(1,2), axis=0)
print("\n\nremoving rows from DataFrame Using label with range() function:\n", df3)Output
Use Case 3: Using the “drop()” Function by Slicing
By utilizing the index slicing approach, you can drop the rows from the Pandas DataFrame. To do so, use the DataFrame with the drop() method using the “dot(.)” operator. Within the “drop()” function braces “()”, access the row index by the “index” attribute with the “dot” notation. Use the index operator “[ ]” to drop the targeted rows in Pandas DataFrame. Here is how the slicing is implemented to drop rows in Pandas DatFrame in Python:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
# Remove Rows by Slicing DataFrame
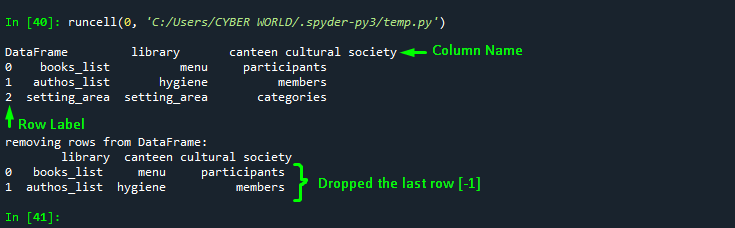
df_1=df1.drop(df1.index[-1])
print("\n\nremoving 1 and last row from DataFrame:\n", df_1)Output
If you are working on the default “index labels” and interested in dropping multiple rows, you can utilize the “index” attribute with the DataFrame using the dot (.) operator. Here’s how you can implement the multiple dows dropping operation:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
df2 = df1.drop([df1.index[1], df1.index[2]])
print("\n\nremoving rows from DataFrame:\n", df2)Output
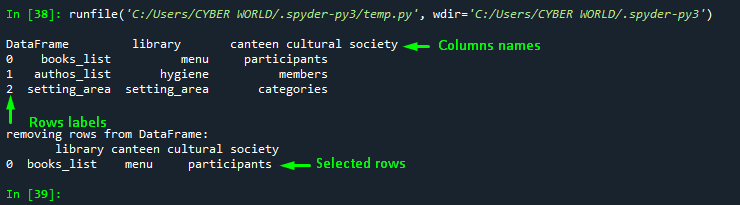
Use Case 4: Dropping Rows by Utilizing “inplace” Parameter
To drop rows in Pandas DataFrame, use the “inplace =False” parameter. Setting the DataFrame “inplace” parameter “False” will display the copy of the DataFrame on the kernel console after dropping the multiple rows from the original DataFrame. Here’s how you can operate:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
index_label=['0','1','2']
# Drop rows by Label indexing
df1 = pd.DataFrame(dict ,index=index_label)
print("\nDataFrame", df1)
df2 = df1.drop(['0', '1'], inplace = False )
print("\n\nremoving rows from DataFrame:\n", df2)Output
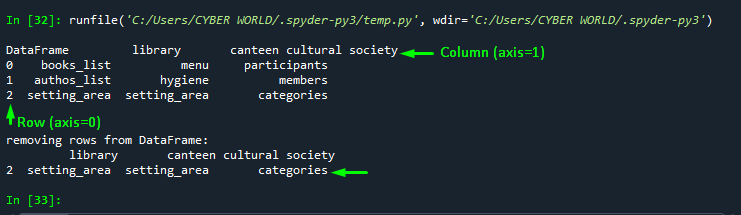
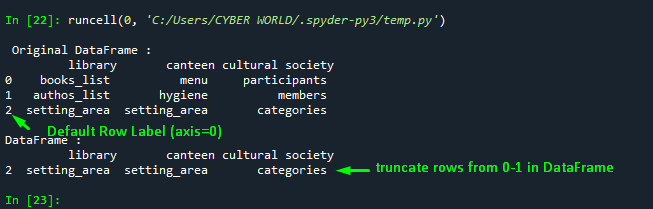
Another practice to drop rows in Pandas DataFrame is to specify the “index” attribute with the dataframe. Within the index, the attribute specifies the multiple rows that you want to drop from the DataFrame:
#truncate dataframe rows
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
#index_label=['0','1','2']
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\n Original DataFrame :\n", df1)
#default index
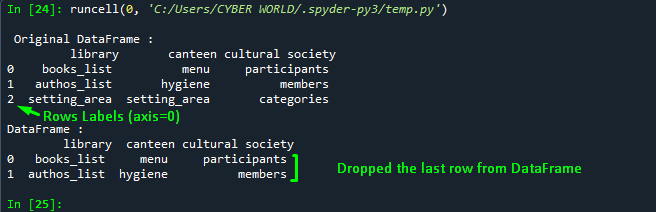
df2= df1.drop(df1.index[0:2], inplace=False)
print("\nDataFrame :\n", df2)Output
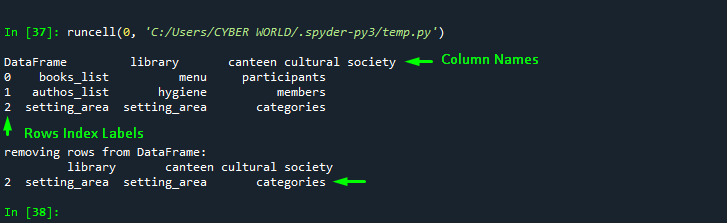
Use Case 5: Dropping Rows by Accessing Index Parameter
To drop rows in Pandas DataFrame in Python access the rows by considering it in the “index” parameter. Specifying multiple rows with the “index” operator “[ ]” and separating them with commas “,” to delete rows from DataFrame:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
index_label=['0','1','2']
# Drop rows by Label indexing
df1 = pd.DataFrame(dict ,index=index_label)
print("\nDataFrame", df1)
df2 = df1.drop(index=['0','1'])
print("\n\nremoving rows from DataFrame:\n", df2)Output
Use Case 6: Dropping Rows by Considering Index Double Bracket Notation
To drop rows in Pandas DataFrame in Python, use the “index double bracket notation”. Within the double bracket index notation “[[ ]]”, specify the rows that you want to delete from the DataFrame in Python:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
df2=df1.drop(df1.index[[1,2]])
print("\n\nremoving rows from DataFrame:\n", df2)Output
Use Case 7: Dropping Rows by Considering Index Slicing
To truncate the rows in Pandas DataFrame in Python, utilize the simple index slicing approach. To implement this, specify the row label with the index operator “[ ]”. In our case:
- The “[2:]” will remove all rows except the “index 2” row
- The “[1:-1]” will drop only the first and last row
- The “[0:2]” will drop the rows at index 2.
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
# Remove Rows by Slicing DataFrame
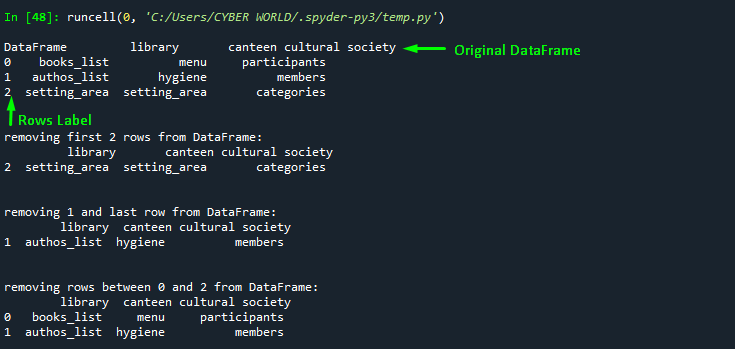
df_2=df1[2:] # removes all rows till index 2 but excludes index 2 from slicing
print("\n\nremoving first 2 rows from DataFrame:\n", df_2)
df_3=df1[1:-1] # Removes first and last row
print("\n\nremoving 1 and last row from DataFrame:\n", df_3)
df_4=df1[0:2] # Return rows between 0 and 2 but excludes index 2 itself
print("\n\nremoving rows between 0 and 2 from DataFrame:\n", df_4)Output
Use Case 8: Dropping Rows by Utilizing drop() function Only
To drop rows in Pandas DataFrame in Python, use the drop() function, and within the function braces “( )” specify the targeted row that you want to drop from DataFrame. If you want to drop multiple rows from the DataFrame, use the index operator “[ ]” and separate each row by commas “,”:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\nDataFrame", df1)
# Remove Rows by Slicing DataFrame
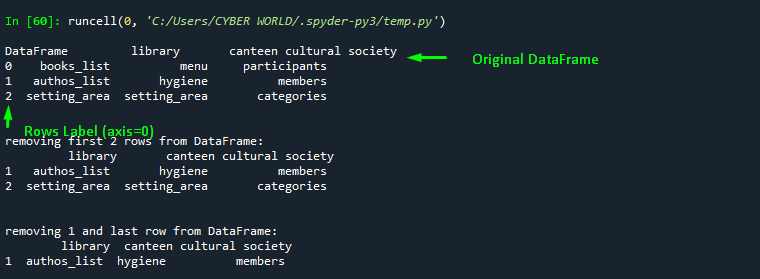
df_2=df1.drop(0) # removes all rows till index 2 but excludes index 2 from slicing
print("\n\nremoving first row from DataFrame:\n", df_2)
df_3=df1.drop([0, 2]) # Removes first and last row
print("\n\nremoving 1 and last row from DataFrame:\n", df_3)Output
Use Case 9: Dropping Rows by Utilizing “iloc” as Attribute
To select particular rows and drop them from dataFrame, use the “iloc” attribute with the DataFrame using the dot(.) notation. The “iloc” in Python takes an integer as an argument. Within the index operator “[ ]” pass the rows that you want to drop from DataFrame. Here’s how you can select multiple rows in a Pandas DataFrame and delete them in Python:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories']}
#index_label=['0','1','2']
# Drop rows by Label indexing
df1 = pd.DataFrame(dict)
print("\n Original DataFrame :\n", df1)
#truncate dataframe rows
#using iloc
df2 = df1.iloc[:2]
print("\nDataFrame :\n", df2)Output
Use Case 10: Dropping Rows by Utilizing drop() function Only
To drop multiple rows utilize the “loc” attribute with the DataFrame in Python using the dot(.) operator. However, to implement the “loc” attribute specifies the particular row name within the index operator “[ ]”
The “loc” attribute reads the row names and provides the particular condition within the index operator “[ ]” to drop the targeted row from the DataFrame:
import pandas as pd
# considering a sample DataFrame
dict = {'library': ['books_list', 'authos_list', 'setting_area'],
'canteen': ['menu', 'hygiene', 'setting_area'],
'cultural society': ['participants', 'members', 'categories'],
'scale': [2,4,5]}
#index_label=['0','1','2']
# Drop rows by Label indexing
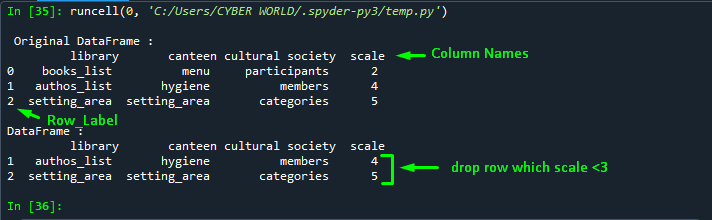
df1 = pd.DataFrame(dict)
print("\n Original DataFrame :\n", df1)
#truncate dataframe rows
#using loc with condition
df2 = df1.loc[df1["scale"] >= (3) ]
print("\nDataFrame :\n", df2)Output
Use Case 11: Dropping Rows by Utilizing the “dropna” Function
Another prevalent approach to delete the rows from Pandas DataFrame in Python is to use the built-in standard package “dropna()”. The “dropna()” function will be beneficial where you are interested in dropping the “NaN” or missing values from the DataFrame. Regardless of considering dimensionality the dropna() will remove the “NaN” values from the entire DataFrame wherever there is a missing value either in rows or in columns:
import pandas as pd
# Drop rows by Label indexing
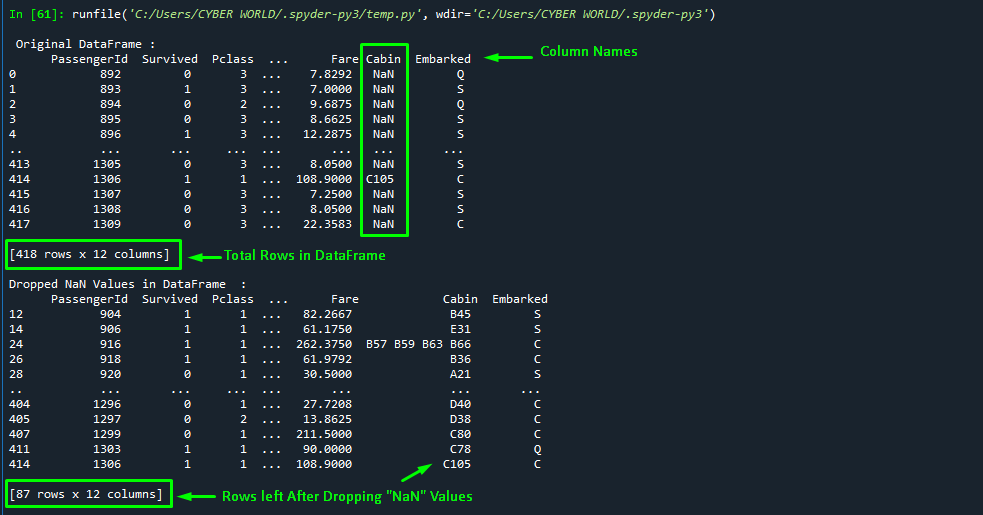
df = pd.read_csv(r'D:\TSL_Python\Datasets\tested.csv')
print("\n Original DataFrame :\n", df)
#truncate dataframe rows
df2=df.dropna()
print("\nDropped NaN Values in DataFrame :\n", df2)Output
Use Case 12: Conditional Dropping Rows in DataFrame
To drop a row based on some condition, utilize the drop() function. Within the “drop()” utilize the conditional operator and the “index” attribute to drop the rows that satisfy the particular condition. Use the index operator “[ ]” to access particular features from the DataFrame:
import pandas as pd
# Drop rows by Label indexing
df = pd.read_csv(r'D:\TSL_Python\Datasets\tested.csv')
df1=df.head()
print("\n Original DataFrame :\n", df1)
#truncate dataframe rows
df2=df.drop(df[(df['PassengerId'] >890) & (df['PassengerId'] < 900)].index, inplace=False)
print("\nDropped rows in DataFrame :\n", df2)Output
That is all about dropping rows from DataFrame in Pandas Python.
Conclusion
To drop rows in Pandas DataFrame in Python, use the drop() function. Within the drop function specify the “row_label” within its braces. However, if the “index label” is manually renamed then utilize the “index operator [ ]” to access multiple rows in DataFrame. However, utilize the “dropna()” function to drop the missing “NaN” values from the DataFrame. This article has demonstrated the prevalent approaches to dropping rows in Pandas DataFrame in Python.