LangChain offers a variety of sets of tools to configure and use the Language models to interact with humans in their language. The major impact is that the model does not require any translator to interpret the questions asked by the user. These models are trained on the dataset containing the complexities of the natural language. The models can simply generate the text after understanding the prompt or message.
The LangChain framework enables the developers to use the sync and async Callback Handler with the components of the language model. The async Callback Handler is recommended for users who want to work with the async API in the LangChain model. The async callbacks can be used to avoid the blocking of the running loops in the model.
How to Use Async Callback Handler in LangChain
The callback handler in LangChain monitors the backend working of multiple processes in the language or chat models. A model in LangChain comprises multiple steps that are executed with the help of various tools and most of them work in the backend. The callbacks are attached with each of these steps so the user can monitor the current state of the model and its processes.
The Python Notebook containing the code for the process is attached here. To learn the process of using the async Callback Handler in LangChain, simply go through the listed steps:
Step 1: Install Modules
Before heading to the process of using the Callback Handler, we need to make sure that the required modules are installed successfully. The first module in the list is the LangChain as we need its dependencies for building the models and using the async Callback Handler with them:
pip install langchain
The next module is the OpenAI which is required to set up the environments for building the language or chat model. Execute the following code with the updated version of the OpenAI to get the dependencies for building and using the models in the LangChain framework:
pip install openai==0.28.1Step 2: Setup OpenAI Environment
After getting the modules on the notebook, set up the environment for the OpenAI platform and use it to get the answers to the questions asked by the user. Import the os and getpass libraries for accessing the operating system and entering the API key of the OpenAI environment. The OpenAI API key can be extracted from the “View API keys” page after signing into the account:
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")Executing the code will ask the user to enter the API key to complete the process of setting up the environment:
Step 3: Importing Libraries
Once the environment setup is complete, import the libraries like asyncio, Any, Dict, and List to use in configuring the Callback Handlers. After that, use the dependencies from the LangChain to import the ChatOpenAI, LLMResults, HumanMessage, and Callback Handlers. These libraries are required to build the language model and then add the async callbacks in the model to monitor its performance:
import asyncio
from typing import Any, Dict, List
from langchain.chat_models import ChatOpenAI
from langchain.schema import LLMResult, HumanMessage
from langchain.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler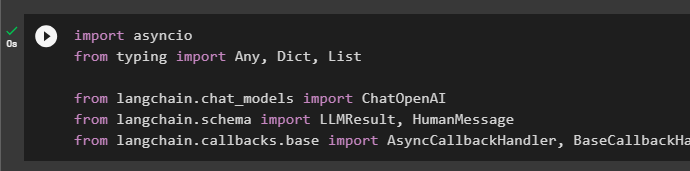
Step 4: Building the AsyncHandler
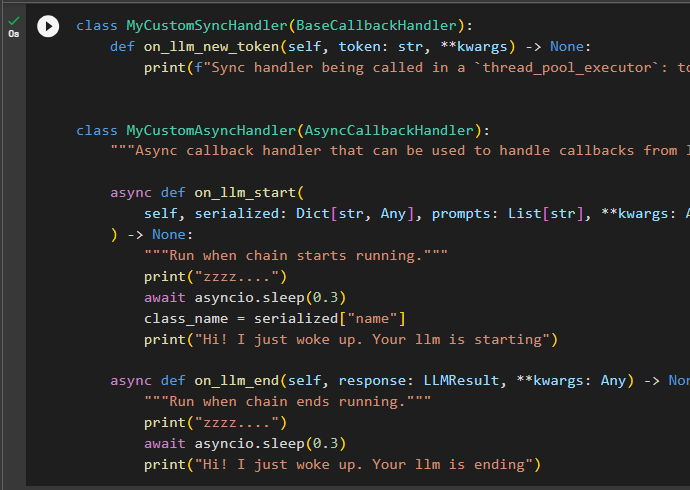
The following is the code to configure the callback manager classes to build the sync and async handlers with the base models as its arguments:
class MyCustomSyncHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"Sync handler being called in a `thread_pool_executor`: token: {token}")
class MyCustomAsyncHandler(AsyncCallbackHandler):
"""Async callback handler that can be used to handle callbacks from langchain"""
async def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Run when the chain starts running"""
print("zzzz....")
await asyncio.sleep(0.3)
class_name = serialized["name"]
print("Hi! I just woke up Your llm is starting")
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when chain ends running"""
print("zzzz....")
await asyncio.sleep(0.3)
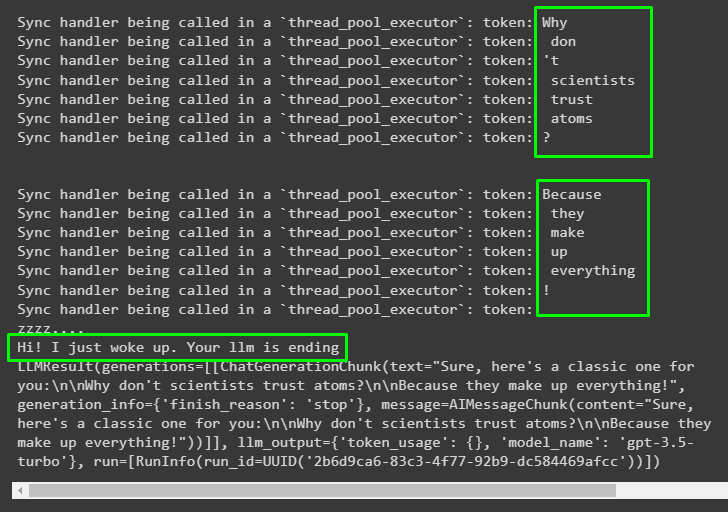
print("Hi! I just woke up Your llm is ending")The code defines the on_llm_new_token() method with the list of the argument and thread-safe executor to avoid issues for the run_in_executor. After that, the code uses the async handler class to define multiple Callback Handlers like on_llm_start and on_llm_end. These callbacks will inform the user about the model when the model starts working and at the end of the model as well. When the language model ends, the Callback Handler informs the process about it. The callbacks will then generates the llm ending message after a few moments:
Step 5: Configuring the Language Model
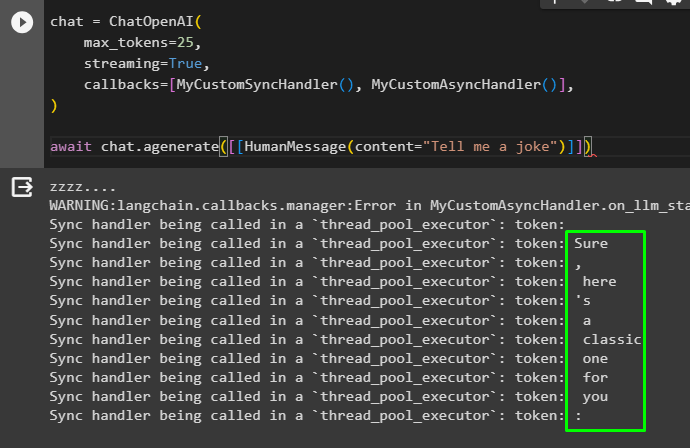
Now that the Callback Handlers are configured, it is time to design the language model using the ChatOpenAI() method. The model has the configurations in its arguments like max_tokens, streaming, and callbacks with the configured methods integrated into it. After that, add the human message with the content asking questions to the model or interacting with it:
chat = ChatOpenAI(
max_tokens=25,
streaming=True,
callbacks=[MyCustomSyncHandler(), MyCustomAsyncHandler()],
)
await chat.agenerate([[HumanMessage(content="Tell me a joke")]])The model has generated the response in the form of streams of tokens of the joke as inquired by the user:
That’s all about the process of using the Async Callback Handler in LangChain.
Conclusion
To use the async Callback Handler in LangChain, simply install the required modules to get the dependencies for building the language models. After getting the modules, set up the environment for extracting the answers or responses from the model. Configure the Callback Handlers using the sync and async classes with the handler methods defined in them. Build the language or chat model to add the Callback Handlers to it and ask the questions by adding the human message to the chat. This guide has displayed the implementations of the sync and async Callback Handlers in LangChain.