LangChain is the framework built by Harrison Chase in October of the year 2022 at a startup organization called Robust Intelligence. It contains the dependencies for building Large Language Models or LLMs for humans to interact with machines and extract the required answers. The models understand the command written in natural language and then extract the information asked by the user.
Human interference in the working of machines can enhance their working capabilities as they are programmed to do certain steps in a process. On the other hand, machines make human logic more efficient by removing the ambiguities or adding improvements to it. Integrating both the human logic and its validation by machine makes a huge impact on the performance of the model.
How to Specify Custom Input Schema With Validation Logic in LangChain?
Building a language model requires the structure of the interface and the backend working of each tool used by the agent. The agent needs to understand each step of the process and the tools required or useful for these steps. The input schema explains the workings of the language model and how the machine performs all the tasks using the tools.
The guide uses the Python notebook to perform all the programming and customize the input schema with validation logic in LangChain and the user can access it from here. To learn the process in detail, the user can simply follow the steps mentioned below:
Step 1: Install Modules
First of all, install the LangChain framework by executing the following command in the Google Collaboratory Notebook. The LangChain framework contains all the dependencies for building the custom input schema with validation logic application or model:
pip install langchain
Install another module which is “tldextract” to get information about the Top-Level Domains or TLDs and generate the answer through the language model:
pip install tldextract > /dev/null
Install the OpenAI module that can be used to access the environment and the functions offered by the OpenAI platform. It also enables the model to generate the text according to the question asked by the user in a structured format:
pip install openai==0.28.1
Step 2: Setup the Environment
After installing the modules and getting their dependencies, set up the environment using the API key from the OpenAI account. Import the os and getpass libraries for accessing the operating system and enter the API key after executing the following code:
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")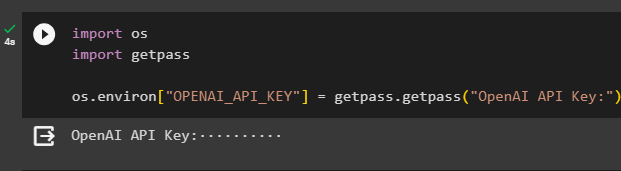
Step 3: Importing Libraries
Now that the environment is set up, use the dependencies like agents to get the libraries like AgentType and initializa_agent to build and invoke the agent for the model. Importing the ChatOpenAI library for configuring the chat model using the chat_model dependency of LangChain. The process also requires the tools to perform the tasks asked by the user like RequestsGetTool and TextRequestsWrapper libraries:
from langchain.agents import AgentType, initialize_agentfrom typing import Any
from langchain.chat_models import ChatOpenAIfrom typing import Dict
from langchain.tools.requests.tool import RequestsGetTool, TextRequestsWrapper
from pydantic import BaseModel, Field, root_validator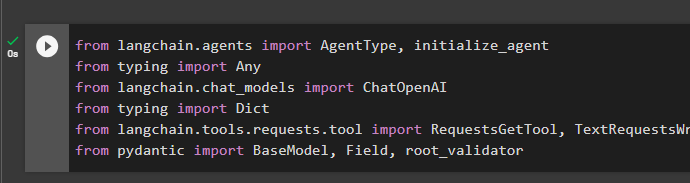
Step 4: Building Model
Once the libraries are imported successfully, define the model variable and initialize it by calling the ChatOpenAI() method. Use the model argument with the type of model that can handle the number of tokens required to perform the logic validation for the custom input schema:
model = ChatOpenAI(model="gpt-3.5-turbo-16k")The “gpt-3.5-turbo-16k” is the OpenAI model that offers 16,385 tokens with training data up to the September of the year 2021:

Step 5: Customize Input Schema
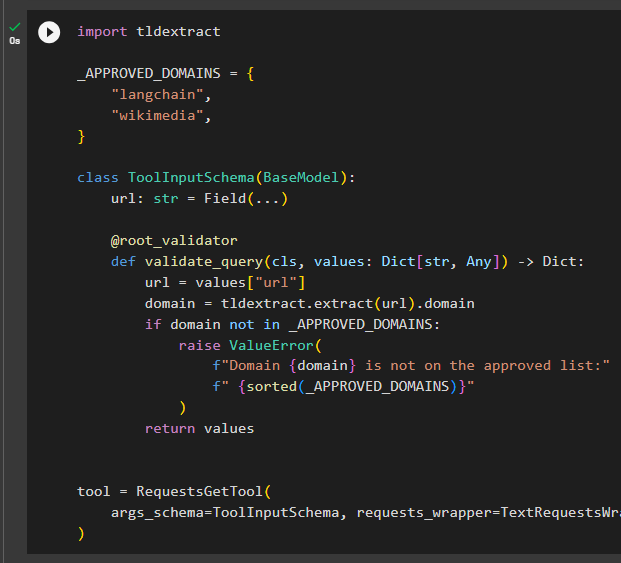
Import the dependency using the “tldextarct” installed in the first step of this guide to extract the answers to the questions related to the domains and subdomains. The following code configures the custom input schema that tells the agent which actions to perform and the tools it can use to answer the question:
import tldextract
_APPROVED_DOMAINS = {
"langchain",
"wikimedia",
}
class ToolInputSchema(BaseModel):
url: str = Field(...)
@root_validator
def validate_query(cls, values: Dict[str, Any]) -> Dict:
url = values["url"]
domain = tldextract.extract(url).domain
if domain not in _APPROVED_DOMAINS:
raise ValueError(
f"Domain {domain} is not on the approved list:"
f" {sorted(_APPROVED_DOMAINS)}"
)
return values
tool = RequestsGetTool(
args_schema=ToolInputSchema, requests_wrapper=TextRequestsWrapper()
)The above code builds the list of approved domains that can be used by the model to answer questions. The approved domain list contains only two domains which are langchain and wikimedia and no other domains are accepted by the model. If any questions are asked related to other domains it will simply result in an error and the model only generates results related to the approved domains. At the end it also builds the tools for extracting information from the domains and building the agent for the agent:
Step 6: Building the Agent
Once the input schema and the tools are configured, use them to build the agents by calling the initialize_agent() method with the components as the arguments. The argument list contains the tool, model, agent, handle-parsing-errors, and verbose to integrate all the components with the agent:
agent = initialize_agent(
[tool], model, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, handle_parsing_errors=True, verbose=False
)
Step 7: Testing the Agent From Approved Domains
Now, define the answer variable with the input question as the argument of the call() function to run the agent:
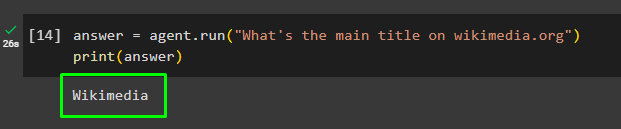
answer = agent.run("What's the main title on wikimedia.org")
print(answer)Running the agent has extracted the answer that is the main title on the wikimedia.org domain as displayed in the following screenshot:
Step 8: Testing the Agent With the Non-Approved Domains
Test the agent by asking the question related to the domain which is not approved by the input schema:
agent.run("What's the main title on google.com")Running the above code will result in an error as google.com is not available in the approved list and the logic validation has been used with the input schema:
That’s all about how to specify a custom input schema with validation logic in LangChain.
Conclusion
To specify the custom input schema with the validation logic in LangChain, install modules like tldextract, OpenAI, and LangChain. These modules contain the dependencies for configuring the input schema and building the language model using the ChatOpenAI() method. After that, integrate the validation logic with the approved domain list to get data from the top-level domains using the tldextract library.
The tools for building the agent are also configured to perform all the tasks to get the output asked by the user by running the agent. The agent validates the logic from the input schema before getting the answer from the domains referred by the user. If the question is related to the approved domains list, the agent will generate the output, and everything else will result in errors. This guide has given a demonstration of how to specify custom input schema with validation logic in LangChain.